Today’s tutorial highlights progress to date through an “end to end” workflow using a real world example of (1) getting, (2) manipulating and (3) enriching a hydrofabric.
If you successfully complete this tutorial, you will create the minimal set of data files (and skills to experiment!) needed for the AWI data stream and NGIAB.
This tutorial can be followed from this webpage which has complete discussion and text surrounding the respective code chunks, or, from the companion R script that can be found here.
Before you jump into this, ensure you have your environment set up by installing R as detailed here and the technical background we will go through today.
Getting Started
# Install -----------------------------------------------------------------
# install.packages("remotes")
# install.packages("powerjoin")
remotes::install_github("NOAA-OWP/hydrofabric")Attach Package
# helper function to use throughout tutorial
make_map = function(file, pois) {
hf = read_hydrofabric(file)
mapview::mapview(hf$catchments) + hf$flowpaths + pois
}
### ---- Sample out files and source for today ---- ###
fs::dir_create("tutorial")
source <- '/Users/mjohnson/hydrofabric/'
reference_file <- "tutorial/poudre.gpkg"
refactored_file <- "tutorial/refactored.gpkg"
aggregated_file <- "tutorial/aggregated.gpkg"
nextgen_file <- "tutorial/poudre_ng.gpkg"
model_atts_file <- "tutorial/poudre_ng_attributes.parquet"
model_weights_file <- "tutorial/poudre_ng_weights.parquet"Building a NextGen Hydrofabric
Get Reference Fabric (subsetting)
For this example, we want to prepare a NextGen hydrofabric and
associated products for the area upstream of NWIS 06752260
that sits on the Cache La
Poudre River in Fort Collins, Colorado. Feel free to use any
particular location of your desire (as relevant to our subsetting
tools), we’ve set up the Lynker-Spatial
Hydrolocation Viewer to make finding an appropriate starting
reference point of interest (POI) easier This POI will define the most
downstream point in our network, and we’ll need to pull out and save
(subset) the reaches which drain to this point in order to collect the
network needed for the model domain.
The lynker-spatial hydrolocation inventory is both a subset and superset of the community POI set. Meaning, we use a subset of the community POIs, and add a selection needed for NextGen modeling. This include (but are not limited to) the NWS LIDs, Coastal/Terrestrail interactions, NWM reservoirs and lakes, coastal gages, and more!
While we focus on the R-based subsetter (hfsubsetR) that
integrates with the other hydrofabric packages here, we
also provide a CLI tool calledhfsubsetCLI
and a (beta) REST
API. and A Python implementation is also forthcoming. You can learn
more about the subsetting tools/options here!
## --- Define starting feature by source and ID
## https://waterdata.usgs.gov/monitoring-location/06752260
## https://reference.geoconnex.us/collections/gages/items?provider_id=06752260
# Use get_subset to build a reference subset
get_subset(
hl_uri = "Gages-06752260",
source = using_local_example,
type = "reference",
hf_version = "2.2",
lyrs = c("divides", "flowlines", "network"),
outfile = reference_file,
overwrite = TRUE
)
st_layers(reference_file)## Driver: GPKG
## Available layers:
## layer_name geometry_type features fields crs_name
## 1 divides Polygon 1122 5 NAD83 / Conus Albers
## 2 flowlines Line String 1129 19 NAD83 / Conus Albers
## 3 network NA 1145 23 <NA>Get some Points of Interest
There are many locations on the network (e.g. dams, gages, etc.) that we want to ensure are preserved in a network manipulation. That means that no matter how a fabric is refactored or aggregated, key hydrolocations persist. This is critical to ensuring cross dataset interoperability, consistent data streams for assimilation and model coupling, and persistent nexus locations.
For this example well read all hydrolocations from the community POI set (GFv20), convert them to spatial points and keep only those within the reference subset domain.
hf = read_hydrofabric(reference_file)
pois = open_dataset(glue("{source}/v2.2/conus_hl")) %>%
filter(hl_source == 'GFv20',
vpuid %in% unique(hf$flowpaths$vpuid),
hf_id %in% hf$flowpaths$id) %>%
collect() %>%
st_as_sf(coords = c("X", "Y"), crs = 5070)
make_map(reference_file, pois)Build a Refactored Fabric
The reference network provides the minimal discretization of the landscape and river network offered by this system. Derived from a traditional cartographic product, we need to remove small river segments that are to short for stable routing calculations and split long narrow catchments that have long flow paths. This process is known as refactoring and is describe in detail in the refactoring section here
refactored = refactor(
reference_file,
split_flines_meters = 10000,
collapse_flines_meters = 1000,
collapse_flines_main_meters = 1000,
pois = pois,
fac = '/vsis3/lynker-spatial/gridded-resources/fac.vrt',
fdr = '/vsis3/lynker-spatial/gridded-resources/fdr.vrt',
outfile = refactored_file
)
make_map(refactored_file, pois)Build an Aggregated Network
This next set of steps will run aggregation tools over the refactored
network. The process of aggregating to a Uniform Distribution.
The first step in doing this is to remap the hydrolocations we enforces
in the refactored fabric. With any refactor execution with
hydrofabric::refactor a lookup table is produced that
relates the original hydrofabric IDs to the new identifiers they became.
A quick join can provide a mapping of hydrolocations to the refactored
network. Passing these to the aggregate_* functions will ensure they are
not aggregated over in the processing.
hydrolocations = read_sf(refactored_file, 'lookup_table') %>%
inner_join(pois, by = c("NHDPlusV2_COMID" = "hf_id")) %>%
select(poi_id, NHDPlusV2_COMID, id = reconciled_ID) %>%
distinct()
head(hydrolocations)## # A tibble: 6 × 3
## poi_id NHDPlusV2_COMID id
## <int> <dbl> <int>
## 1 37345 2899997 2
## 2 37014 2899553 10
## 3 36913 2900669 15
## 4 36920 2900581 24
## 5 36914 2900571 28
## 6 36664 2898115 44
aggregate_to_distribution(
gpkg = refactored_file,
hydrolocations = hydrolocations,
ideal_size_sqkm = 10,
min_length_km = 1,
min_area_sqkm = 3,
outfile = aggregated_file,
overwrite = TRUE )
make_map(aggregated_file, pois)Generate a NextGen Network
In order to make this hydrofabric compliant with the NextGen flowline-to-nexus topology and mapping, we’ll run the following over our aggregated network.
unlink(nextgen_file)
apply_nexus_topology(aggregated_file, export_gpkg = nextgen_file)## [1] "tutorial/poudre_ng.gpkg"
hf = read_hydrofabric(nextgen_file)
make_map(nextgen_file, read_sf(nextgen_file, "nexus"))And there you have it! This is the minimal set of information needed in a NextGen hydrofabric!
Enriching the Network: Divides
There is a lot of divide level information that can be useful for running hydrologic models, training and validating machine learning models (e.g. LSTM, roughness, 3D hydrofabric). This sort of data typically includes things like soil type, average basin slope, and land cover. Divide level spatial information needs to be summarized from one unit into the divide level in one of the following ways:
- Grid –> POLYGON (with appropriate grid cell weighting)
- Smaller POLYGON –> Bigger POLYGON
- Bigger POLYGON –> Smaller POLYGON
The easiest way to accomplish this is to use to use use the climateR package to
access data, and zonal to rapidly summarize gridded data to the POLYGON
scale. Both are core components of the NOAA-OWP/hydrofabric
meta package and should already be loaded!
These summarizations can be as simple as deriving a mean value, or as complex user-defined summaries. We will highlight each of these below as we walk through the steps needed to build the divide-level data needed to run CFE, NOM, PET, and generate forcing’s.
Derive the divide-level data needed for CFE/NOM/PET
To start, we will define the principle lynker-spatial gridded
resources end point, and extract the divides from our
nextgen_file:
vsi <- "/vsis3/lynker-spatial/gridded-resources"
div <- read_sf(nextgen_file, "divides")NOAH OWP Varibables
If you have used the NWM data before you’ll know the data distributed in the NetCDF domain files is packed unconventionally, lacks spatial information, and is not optimized for piecemeal access. As such, relevant layers were extracted and turned into Cloud Optimized GeoTiffs (COG) and distributed egress free. We’ll demonstrate a few of the different ways we can summerise these in the next example. All of these are grid –> POLYGON summaries that utilize mode, mean, and geometric mean summaries.
# Desired variables
nom_vars <- c("bexp", "dksat", "psisat", "smcmax", "smcwlt")
# Each of these is four layers, we only want the top layer of each
r = rast(glue("{vsi}/nwm/conus/{nom_vars}.tif"), lyrs = seq(1,length(nom_vars)*4, by = 4))
# Get Mode Beta parameter
modes = execute_zonal(r[[1]],
fun = mode,
div, ID = "divide_id",
join = FALSE) %>%
setNames(gsub("fun.", "", names(.)))
# Get Geometric Mean of Saturated soil hydraulic conductivity, and matric potential
gm = execute_zonal(r[[2:3]],
fun = geometric_mean,
div, ID = "divide_id",
join = FALSE) %>%
setNames(gsub("fun.", "", names(.)))
# Get Mean Saturated value of soil moisture and Wilting point soil moisture
m = execute_zonal(r[[4:5]],
fun = "mean",
div, ID = "divide_id",
join = FALSE) %>%
setNames(gsub("mean.", "", names(.)))
# Merge all tables into one
d1 <- power_full_join(list(modes, gm, m), by = "divide_id")GW Routing Parameters
Aspects of these base model formulations that include the
representation of groundwater discharge/baseflow in their simulation
require parameters to characterize their bucket models. These include
Coeff which is the bucket model coefficient,
Expon which is the bucket model exponent, and
Zmax which is the conceptual maximum depth of the
bucket.
GW data is stored in the conus_routelink parquet store
(sourced from the GWBUCKPARM_CONUS_FullRouting.nc in the
latest NWM). The assumption here is that the area from the reference
features are substituted in the the NHDPlus based
GWBUCKPARM_CONUS_FullRouting.nc variables. Given the nature
of the divide restructuring, this is an acceptable
generalization.
These are POLYGON –> POLYGON summaries that area weight the respective values at the NHDPlus scale to our aggregated NextGen network.
NOTE the lazy join prior to data collection!
crosswalk <- as_sqlite(nextgen_file, "network") |>
select(hf_id, divide_id) |>
collect()
d2 <- open_dataset(glue("{source}/v2.2/reference/conus_routelink")) |>
select(hf_id , starts_with("gw_")) |>
inner_join(mutate(crosswalk, hf_id = as.integer(hf_id)), by = "hf_id") |>
group_by(divide_id) |>
collect() |>
summarize(
gw_Coeff = round(weighted.mean(gw_Coeff, w = gw_Area_sqkm, na.rm = TRUE), 9),
gw_Zmax_mm = round(weighted.mean(gw_Zmax_mm, w = gw_Area_sqkm, na.rm = TRUE), 9),
gw_Expon = mode(floor(gw_Expon))
)Forcing Downscaling Base Data
Outside of populating model formulations, key catchment attributes are required to replicate the forcing engine implemented in the WRF-Hydro and NWM models. The hydrofabric provides the means to downscale those data using attributes like a catchment centroid, mean elevation and slope, and the circular mean of aspect.
Centroid
d3 <- st_centroid(div) |>
st_transform(4326) |>
st_coordinates() |>
data.frame() |>
mutate(divide_id = div$divide_id)Elevation derived inputs
dem_vars <- c("elev", "slope", "aspect")
r <- rast(glue('{vsi}/250m_grids/usgs_250m_{dem_vars}.tif'))
d4 <- execute_zonal(r[[1:2]],
div, ID = "divide_id",
join = FALSE) |>
setNames(c("divide_id", "elevation_mean", " slope"))
d5 <- execute_zonal(r[[3]],
div, ID = "divide_id", fun = circular_mean,
join = FALSE) |>
setNames(c("divide_id", "aspect_c_mean"))
model_attributes <- power_full_join(list(d1, d2, d3, d4, d5), by = "divide_id")Forcing Weight Grids
Tools like CIROH
ngen-datastream and NextGen in a Box not only use the divide level
information to downscale data to the NWM forcing grid, but leverage
precomputed weights to summarize the forcing information to the divide
level each timestep. Doing this in an efficient manner requires pointing
to a template grid (here the
medium_range.forcing) and executing the
weight_grid function from zonal to compute the
percentage of each cell that is covered by each divide. A template grid
is one in which the structure (cell
resolution, grid spacing etc.), but not the input data, is
important.
NOTE: If using a pre generated network, the forcing weights are a subsetable layer in our subseting tools (e.g
{source}/{version}/{type}/{domain}_forcing-weights). It can also be generated on the fly with the REST API for a queried subset (see more in thedocs).
Writing the Data to External Files
Both the divide level attribute data and the forcing weights can be
written to sidecar parquet files that are hosted alongside the
nextgen_file GPKG. The combination of these three files
ensures you have the basic information needed to execute a NGIAB
simulation.
Now it’s as easy as plugging these generated data files into the NextGen Datastream to run a NextGen simulation. Checkout “NextGen Simulation Development Tools” tomorrow at 1:30 PM in room 6619 to see it in action!
In each, the primary key is divide_id which can be used
to relate, join, and parse the files.
write_parquet(model_attributes, model_atts_file)
write_parquet(w, model_weights_file)Enriching the Network: Flowpaths
While still experimental, one of newest data sets we are building to
support hydraulic and hydrologic routing methods and enhanced FIM
support is a representation of channel shape (3D Hydrofabric). To finish
this tutorial we’ll demonstrate how to access
cross section data and add flowpath attributes
to your nextgen_file. More documentation is coming soon
related to the derivation, use, and manipulation of these; but as a
sneak peak, feel free to check out the related background on open source
software used to generate training data published in JOSS here,
the machine learning methods used for estimating reach
level roughness, and in channel and bankfull channel
properties.
Machine Learned Channel Properties
Our ML properties are estimated using a wide range of geospatial
inputs and NWM flow frequencies. All of these were estimated for the
reference fabric and can be accessed in the conus_routelink
parquet store following the same patterns used above of
{source}/{version}/{type}/{domain}_{layer}. Here we’ll
demonstrate how to find the attributes associated with the most
downstream (max hydroseq) POI in the NextGen file:
crosswalk <- as_sqlite(nextgen_file, "network") |>
select(hf_id, hydroseq, poi_id) |>
filter(!is.na(poi_id)) %>%
collect() %>%
slice_max(hydroseq)
# Available ML outputs
open_dataset(glue("{source}/v2.2/reference/conus_routelink/")) |>
select(hf_id, starts_with("ml_")) ## FileSystemDataset (query)
## hf_id: int32
## ml_tw_inchan_m: double
## ml_tw_bf_m: double
## ml_y_inchan_m: double
## ml_y_bf_m: double
## ml_ahg_c: double
## ml_ahg_f: double
## ml_ahg_a: double
## ml_ahg_b: double
## ml_ahg_k: double
## ml_ahg_m: double
## ml_r: double
## ml_bf_channel_area_m2: double
## ml_inchan_channel_area_m2: double
## ml_bf_channel_perimeter_m: double
## ml_inchan_channel_perimeter_m: double
## ml_roughness: double
## ml_hf_source: string
##
## See $.data for the source Arrow object
# Get the cross section for the most downstream POI
(cs <- open_dataset(glue("{source}/v2.2/reference/conus_routelink/")) |>
select(hf_id, ml_y_bf_m, ml_tw_bf_m, ml_r) %>%
inner_join(mutate(crosswalk, hf_id = as.integer(hf_id)), by = "hf_id") |>
collect() %>%
summarise(TW = mean(ml_tw_bf_m),
r = mean(ml_r),
Y = mean(ml_y_bf_m),
poi_id = poi_id[1]))## # A tibble: 1 × 4
## TW r Y poi_id
## <dbl> <dbl> <dbl> <chr>
## 1 37.9 24.1 1.39 37014With the defined bankfull width, depth and
r coefficient, we can use AHGestimation (not
part of NOAA-OWP/hydrofabric core as elaborated above) to
derive a symmetric cross section based on the foundations of At A
Station Hydraulic Geometry (AHG) representations:
#remotes::install_github("mikejohnson51/AHGestimation")
bathy = AHGestimation::cross_section(r = cs$r, TW = cs$TW, Ymax = cs$Y)
plot(bathy$x, bathy$Y, type = "l",
ylab = "Releative distance (m)",
xlab = "Depth (m)",
main = glue("Average XS at POI: {cs$poi_id}"))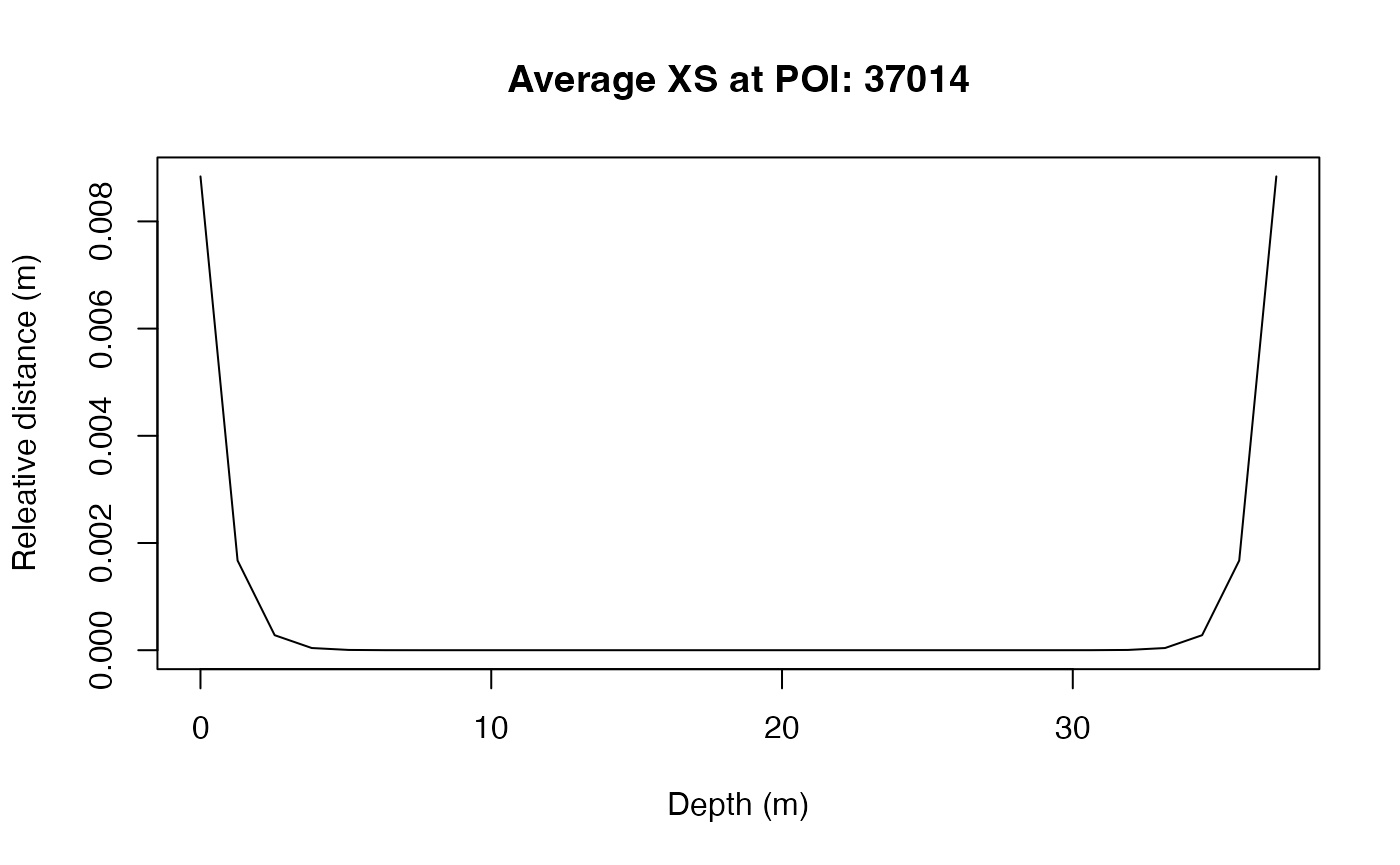
Extacting Cross Sections:
Cross sections have been derived for the NextGen hydrofabric
v2.1.1 (identical to v20.1 except for
restructuring to the cloud native structure). Cross sections are created
in three steps
- creating transects perpendicular to the reference flowlines and extended to the edges of the 100yr floodplains. 2. DEM elevations extracted along each transect and the locations are classified as left/right bank, channel, and channel bottom
- ML injected bathymetry (XSml) that is ensured to be monotonically decreasing along mainstem and at junction locations.
From these, stage-varying cross sectional areas, flowpath slopes, wetted perimeter, and other critical hydraulic parameters can be estimated from a hydro-referenced, interoporable, and lightweight dataset that can scale from reference to derived product.
# install.packages("plotly")
library(plotly)
crosswalk <- as_sqlite(nextgen_file, "network") |>
select(hf_id, id, toid, divide_id, hydroseq, poi_id) |>
collect() %>%
slice_max(hydroseq)
cw = open_dataset(glue('{source}/v2.1.1/nextgen/conus_network')) %>%
semi_join(crosswalk, by = "hf_id") %>%
collect()
message(sum(cw$lengthkm), " kilometers of river")
(xs = open_dataset(glue('{source}/v2.1.1/nextgen/conus_xs')))## FileSystemDataset with 21 Parquet files
## hf_id: string
## cs_id: int32
## pt_id: int32
## relative_distance: double
## cs_lengthm: double
## class: string
## point_type: string
## X: double
## Y: double
## Z: double
## Z_source: large_string
## vpuid: string
filter(xs, vpuid %in% unique(cw$vpuid), hf_id %in% unique(cw$id)) %>%
group_by(hf_id, cs_id) %>%
collect() %>%
mutate(uid = cur_group_id()) %>%
plot_ly(x = ~X, y = ~Y, z = ~Z, split = ~as.factor(uid),
type = 'scatter3d', mode = 'markers+lines',
line = list(width = 3), marker = list(size = 2)) %>%
layout(list(aspectmode='manual',
aspectratio = list(x=100, y=100, z=1)),
showlegend = FALSE)Populate Flowpath Attributes
Slowly the ML enhanced DEM-based cross sections are being used to
supplement a national Routelink file (conus_routelink) that
is complete with the routing attributes need for both t-route and WRF-Hydro / NWM to
execute. We are striving to implement the routelink file at the
reference fabric level meaning it can be expended to
any derived product. As such, the length average contribution of each
reference flowline to its aggregated flowpath needs to be calculated.
This can be done in the following way:
add_flowpath_attributes(nextgen_file, source = source)## [1] "tutorial/poudre_ng.gpkg"## # A tibble: 6 × 13
## fid id rl_Qi_m3s rl_MusX rl_n rl_So rl_ChSlp rl_BtmWdth_m
## <int> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 wb-1 0 0.2 0.06 0.0197 0.517 3.91
## 2 2 wb-10 0 0.2 0.0565 0.0481 0.420 9.14
## 3 3 wb-100 0 0.2 0.06 0.0971 0.641 2.33
## 4 4 wb-101 0 0.2 0.06 0.064 0.634 2.39
## 5 5 wb-102 0 0.2 0.06 0.0726 0.628 2.45
## 6 6 wb-103 0 0.2 0.06 0.0552 0.679 2.05
## # ℹ 5 more variables: rl_Kchan_mmhr <dbl>, rl_nCC <dbl>, rl_TopWdthCC_m <dbl>,
## # rl_TopWdth_m <dbl>, length_m <dbl>Adding GPKG Symbology
As a group of geographers, we feel maps are important and were tired
of the random hodge-podge of symbologies created by QGIS. As such, a
final (optional) touch is to add some symbology layers (QML) to the
generated GPKG with the append_style function!
append_style(nextgen_file, layer_names = c("divides", "flowpaths", "nexus"))## [1] "tutorial/poudre_ng.gpkg"Let’s open it with QGIS and see our final product!

 And with
that you are ready to experiment, derive, and access your own enriched
hydrofabics!
And with
that you are ready to experiment, derive, and access your own enriched
hydrofabics!