Introduction
Mike Johnson
Lynker, NOAA-AffiliateSource:
vignettes/01-intro-deep-dive.Rmd
01-intro-deep-dive.RmdWhat is a hydrofabric?
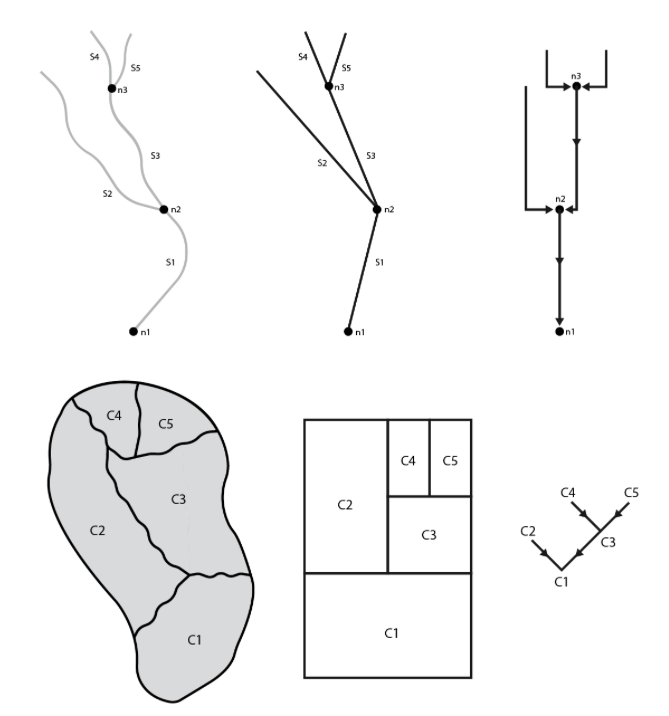
The first question generally raised is, “what is a hydrofabric?” To date, the term has been been used to describe artifacts as narrow as a set of cartographic lines, all the way to the entire spatial data architecture needed to map and model the flow of water and flood extents. For our purposes here, the hydrofabric is the base data that allows NextGen to run. It provides:
- the landscape and flow network discritizations
- the connectivity (topology) of the network features
- the locations where information will be reported (nexus’s)
- the divide and flowpath attributes needed to support hydrologic modeling and routing
The hydrofabric also establishes a system of linked data and Web infrastructure that can relate to, and extract from, linked sources like:
- the USGS Next Generation Monitoring Location Pages (e.g. here)
- The Internet of Water Geoconnex PID registry (e.g. here)
- climate-catalogs (e.g. here)
- landscape characteristic catalogs

Who cares about a hydrofabric?
Discritizing the land surface into computational elements is fundamental to all modeling tasks. Without it, distributed and lumped models have no way to apply the needed model formulations or computer science applications to achieve meaningful results. Therefore anyone who cares about the science and application of water resource modeling should care about the underlying data as it drives the locations where forecasts are made, the attributes that inform a model, and the spatial elements in which formulation are valid.
However, describing the earths surface - particularly at continental scales - is a tricky task. Automated techniques can get us a long way in representation, however the modeling task at hand and local knowledge should be used in developing an authoritative product. Through time, local knowledge has been collected in a number of places, but never centralized. Further, one off products (like the NHDPlus) have been used to guide all modeling task even in cases when its resolution, or representation is not well suited.
The aim of NOAAs work in this space is to develop a federal reference fabric to support all flavors of modeling, and a national instance of that reference fabric to support heterogeneous model application.
Equally important is the software tools to support flexibility and community uptake; the data models to support interoperability, community engagement, and long term stability; and a reference data set with the quality assurances that when one uses the product they are getting a well vetted resource that will be able to play nicely with the growing Ngen framework.
Current Version:
The most up to date NextGen hydrofabric and resources can be accessed from the public facing Lynker Spatial account.
In practice we strive to develop these products to take advantage of the following:
Leading data science
Distribution System
- s3 (through AWS)
Hydroscience Conceptual Models & Web Infastrucutre
- The hydrofabric features are grounded in the OGC HY Feature conceptual model.
The OGC Engineering Report “Hydrologic Modeling and River Corridor Applications of HY_Features Concepts”
The Network Linked Data Index (NLDI) here, and here and here
The lynker-spatial [hydrolocation inventory]
Formal Realization Representations
- The HY Features conceptual model is conflated with the Simple Feature Access Spatial Data model to provide a logical model for how the feature realizations are represented in the hydrofabric data model.

Software
Extracting subsets from the primary hydrofabric data product does not require code, however, if you are eager to build, modify and expand on the existing products the
remotes::install_github("NOAA-OWP/hydrofabric")Hydrofabric provides a easy install for a variety of hydroscience, data science, and spatial libraries that are needed.
Attaching this library, similar to the tidyverse,
installs and loads a set of software designed to manipulate, modify,
describe, process, and quantify hydrologic networks and land surface
attributes:
## ── Attaching packages ───────────────────────────────────── hydrofabric 0.1.0 ──## ✔ dplyr 1.1.4 ✔ zonal 0.0.3
## ✔ climateR 0.3.5 ✔ hfsubsetR 0.0.9
## ✔ nhdplusTools 1.2.0 ✔ ngen.hydrofab 0.0.4
## ✔ hydrofab 0.5.2 ✔ terra 1.7.78## ── Conflicts ──────────────────────────────────────── hydrofabric_conflicts() ──
## ✖ terra::plot() masks climateR::plot()##
## Attaching package: 'hydrofabric'## The following objects are masked _by_ 'package:hydrofab':
##
## append_style, hf_dmlibrary(hydrofabric) will load the core packages
(alphabetical):
- climateR for accessing federated data stores for parameter and attributes estimation
- hfsubsetR for cloud-based hydrofabric subsetting
- hydrofab a tool set for “fabricating” multiscale hydrofabrics
- ngen.hydrofab NextGen extensions for hydrofab
- nhdplusTools for network manipulation
- zonal for catchment parameter estimation
Additionally it will load key geospatial data science libraries:
-
dplyr(data.frames) -
sf(vector) -
terra(raster)